MarkWeb: Enhancing performance and usability
As part of my ongoing efforts to improve MarkWeb, I’ve implemented several key changes to enhance performance, security, and user experience. This post details the technical aspects of these updates.
Security Enhancements
Polyfill Fix
polyfill.io is used for loading polyfills (code that provides modern functionality on older browsers). Mathjax, the library MarkWeb uses for rendering mathematical equations, relies on polyfills for compatibility with older browsers.
In light of the supply chain attack on polyfill.io, the link to polyfill.io has been replaced with a link to Cloudflare’s mirror. This change ensures that the polyfills are served securely and reliably.
old polyfill.io link:
<script src="https://polyfill.io/v3/polyfill.min.js?features=es6"></script>
new Cloudflare mirror link:
<script src="https://cdnjs.cloudflare.com/polyfill/v3/polyfill.min.js?version=4.8.0&features=es6"></script>
Proxy Security
Another security feature coming eventually is rate limiting. This is typically done by using the remote_address (client’s IP address). However, as mentioned in the earlier blog, Cloudflare is used as a proxy for our app, which means that the client’s IP will appear to be the Cloudflare proxy server. To determine the proper client IP address, the X-Forwarded-For header is used. For each proxy, an IP address is concatenated to the X-Forwarded-For header.
X-Forwarded-For: <client>, <proxy1>, <proxy2>
Because we trust Cloudflare as a proxy, <proxy1> should equal a Cloudflare proxy IP address, while <client> should be the remote_address we use to rate limit. However, this header can be easily spoofed by attackers, leading to a false IP address being used for access control. For example, we can use curl to add a proxy IP to be forwarded to the Cloudflare proxy. In the example below, we use a special route that returns headers and request.remote_addr, among other info.
curl -H "X-Forwarded-For: 127.0.0.1, 1.1.1.1" http://markweb.test:5000/debug/test_proxy
{
"CF-Connecting-IP": null,
"Client IP": "127.0.0.1",
"Host": "markweb.test:5000",
"Remote Addr": "127.0.0.1",
"Scheme": "http",
"X-Forwarded-For": "127.0.0.1, 1.1.1.1, 2.2.2.2",
"X-Forwarded-Host": null,
"X-Forwarded-Port": null,
"X-Forwarded-Prefix": null,
"X-Forwarded-Proto": null
}
In the above scenario, all requests are passed through a proxy with IP address 2.2.2.2. The true client IP is 1.1.1.1, but we set the X-Forwarded-For header to 127.0.0.1, 1.1.1.1. By default, Flask will blindly trust the first X-Forwarded-For header value as the true client IP address, setting request.remote_addr to this value. We successfully spoofed the request, which lets us bypass any IP-based rate limiting or access IP restricted routes and features.
To avoid this, we let the Flask app know how many proxies to trust the header for. This is done with Werkzeug’s ProxyFix middleware. For a single proxy like Cloudflare, we setup the middleware as follows:
from werkzeug.middleware.proxy_fix import ProxyFix
# ...
app.wsgi_app = ProxyFix(app.wsgi_app, x_for=2, x_proto=1, x_host=1, x_port=1, x_prefix=1)
This trusts the second to last value of the X-Forwarded-For header, or the one right before the last proxy.
curl -H "X-Forwarded-For: 127.0.0.1, 1.1.1.1" http://markweb.test:5000/debug/test_proxy
{
"CF-Connecting-IP": null,
"Client IP": "127.0.0.1",
"Host": "markweb.test:5000",
"Remote Addr": "1.1.1.1",
"Scheme": "http",
"X-Forwarded-For": "127.0.0.1, 1.1.1.1, 2.2.2.2",
"X-Forwarded-Host": null,
"X-Forwarded-Port": null,
"X-Forwarded-Prefix": null,
"X-Forwarded-Proto": null
}
Now, the client IP field (determined from X-Forwarded-For) is the untrusted first value. The remote address field, which is used in the application for IP-related features, is properly set to 1.1.1.1, based on the number of values to trust. The rest of the X-Forwarded header values should only be trusted for 1 value (set by Cloudflare proxy), and so we set those parameters to 1. More info on the ProxyFix middleware is in Werkzeug’s documentation.
You may also notice the CF-Connecting-IP header is printed in our debug output. This is a non-standard header that Cloudflare uses to immediately communicate the client IP. Because we are only using one proxy, we can write code more specific to Cloudflare’s proxy service as follows:
class CloudflareProxyFix:
def __init__(self, app):
self.app = app
def __call__(self, environ, start_response):
environ_get = environ.get
environ["cloudflare_proxy_fix.orig"] = {
"REMOTE_ADDR": environ_get("REMOTE_ADDR")
}
cf_connecting_ip = environ_get('HTTP_CF_CONNECTING_IP')
if cf_connecting_ip:
environ["REMOTE_ADDR"] = cf_connecting_ip
return self.app(environ, start_response)
Following the conventions of the original ProxyFix, we set environ_get to environ.get for efficiency, and then update the environment with the original value of REMOTE_ADDR, for debugging and logging purposes. Then, if the CF-Connecting-IP header is present, we set the remote address to it. Because CF-Connecting-IP is always set by Cloudflare and any client value is ignored, we can generally avoid implementing extra checks for this header.
Performance Optimizations
Efficient Static File Serving
One of the most useful things to do when first optimizing a web application is to profile it. To start profiling, I added a profiling config flag to the app. When this flag is set, the app will use the Werkzeug profiler middleware to profile the app.
if app.config['PROFILER']:
app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions=[0.1])
With restrictions set to 0.1, this middleware prints the top 10% of the slowest function calls, sorted by total time taken.
--------------------------------------------------------------------------------
PATH: '/'
2471 function calls (2434 primitive calls) in 0.874 seconds
Ordered by: internal time, call count
List reduced from 737 to 74 due to restriction <0.1>
ncalls tottime percall cumtime percall filename:lineno(function)
2 0.662 0.331 0.662 0.331 {method 'execute' of 'psycopg2.extensions.cursor' objects}
2 0.201 0.100 0.201 0.100 {method 'rollback' of 'psycopg2.extensions.connection' objects}
4 0.002 0.000 0.002 0.000 {method 'write' of '_io.TextIOWrapper' objects}
1 0.000 0.000 0.000 0.000 {built-in method nt.stat}
195 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}
3/1 0.000 0.000 0.000 0.000 c:\users\denni\markweb\.venv\lib\site-packages\sqlalchemy\sql\cache_key.py:221(_gen_cache_key)
...
In addition to showing the time taken for Flask to serve the path requested, it also shows the profile of all other functions called, including those serving favicon.ico and other static files. One thing I noticed when looking at the static file profiles was that database queries were being made for each static file.
This was because the before_app_request decorator was being used to load the logged-in user. This decorator is called for every request, including those for static files. To avoid this, I added a check to skip the user loading for static files and other non-essential paths.
@bp.before_app_request
def load_logged_in_user():
if request.path.startswith('/static') or request.path in [
'/favicon.ico', '/robots.txt',
'/sitemap.xml', '/stripe_webhook'
]:
return
user_id = session.get('user_id')
if user_id is None:
g.user = None
else:
g.user = db.session.execute(
db.select(User).filter_by(id=user_id)
).scalar()
This change lets Flask instantly serve static files without making any database queries. The g object used in this function is a special object that Flask uses to store data that is accessible throughout the request lifecycle. This object is cleared after each request, so it is safe to store data that is only needed for the current request.
Further optimizations can be made to this function by only loading user data on select routes. However, the username is displayed in the navbar, which is present on every page. We could use session cookies to store the user’s username, but this cookie would need to be evicted when the username changes. This would require a database query or some form of synchronization between clients to check if the username has changed, which would further complicate the logic and negate the performance benefits of using a cookie.
Database Optimizations
After testing, I noticed that one of the slowest parts of the app was loading blog posts. According to the profiler, converting the blog post from Markdown to HTML often took several hundred milliseconds. This was because the Markdown was being converted to HTML on every request, even if the blog post had not changed.
To avoid this, I added a column to the blog post table to store the HTML version of the blog post. This column is updated whenever the blog post is created or updated. This change significantly reduced the time taken to load blog posts, with cache hits taking less than 40ms.
class Post(db.Model):
__tablename__ = 'post'
id = Column(Integer, primary_key=True, autoincrement=True)
user_id = Column(Integer, ForeignKey('users.id', ondelete='CASCADE'), nullable=False)
created = Column(DateTime, nullable=False, server_default=func.current_timestamp())
title = Column(Text, nullable=False)
body = Column(Text, nullable=False)
body_html = Column(Text, nullable=False) # new column for HTML version of the post
user = relationship('User', back_populates='posts')
Another optimization was made when making queries from routes under a user’s subdomain. Although usernames in MarkWeb are case-sensitive, the subdomain is case-insensitive. This means that the subdomain user.markweb.test is the same as USER.markweb.test. To prevent creating usernames that would result in duplicate subdomains and to speed up queries, each username is stored in lowercase alongside the cased username.
class User(db.Model):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(Text, unique=True, nullable=False)
username_lower = Column(Text, unique=True, nullable=False)
email = Column(Text, unique=True, nullable=False)
password = Column(Text, nullable=False)
# ...
def __init__(self, *args, **kwargs):
super(User, self).__init__(*args, **kwargs)
self.username_lower = self.username.lower()
By defining the constructor method, we can ensure that the username_lower field is always set to the lowercase version of the username. This way, we can query the database using the lowercase version of the username, which is faster and more efficient than using a case-insensitive query.
After all optimizations, blogs load much faster, with DOMContentLoaded times reduced to under 500ms.
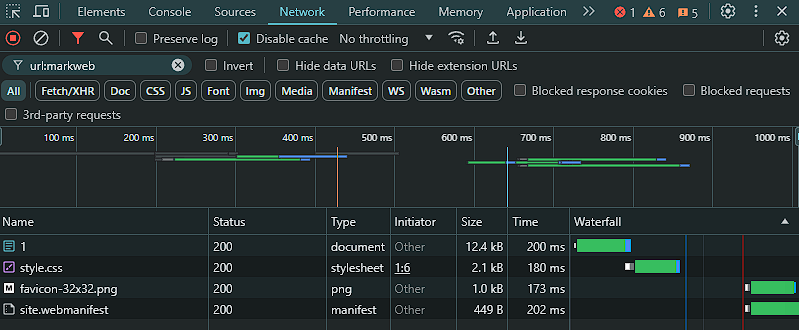
Database indices were also added to speed up queries. For example, the username_lower field in the User table was indexed to speed up queries for user subdomains.
Usability
Only a small change was made to improve usability in this update, but the change is similar to more to come.
Now, users can upload markdown files directly to the blog post editor. This feature is useful for users who prefer to write blog posts in their favorite text editor. I plan to add more ways to import content into MarkWeb, such as importing from cloud storage, GitHub, zipped directories, and other blogging platforms. The same will be true for options to export content from MarkWeb, such as exporting to PDF, Word, and other formats. The goal is to ensure user ownership of their content first.
The below code adds an input element to the blog post editor that allows users to upload a markdown file. When a file is uploaded, the contents of the file are read and set as the value of the editor, without sending the file to the server.
<div>
<label for="md_file">Upload Markdown File</label>
<input type="file" id="md_file" accept=".md,.markdown,.txt" style="display: none;">
</div>
<script>
document.getElementById('md_file').addEventListener('change', function(event) {
const file = event.target.files[0];
if (file) {
const reader = new FileReader();
reader.onload = function(e) {
simplemde.value(e.target.result);
event.target.value = '';
};
reader.readAsText(file);
}
});
</script>
Conclusion
With the backend in a more stable state, I plan to focus on the frontend in the next update. This will include improving the import/export features, adding more customization options, and adding analytics.
With more time to work on MarkWeb, I hope to bring it to users in the coming week.